記得剛入社會的第一個專案是使用 struts2, 和原先學校內學長教的 Controller/Service/Repository 三層架構幾乎一樣, 但我也是第一次體會到一個 Service 內有幾百行程式碼是什麼感覺.
在完成 struts2 的洗禮之後, 我便被調往一個大型的單體支付系統專案, 我也是後來在那裡認識了前一篇的 K 老弟.
在那個支付系統專案中, 我印象很深刻, 他的設計多了一層 Service, 有點 clean archticture 內 usecase 的味道, 我其實當時很不解為什麼 Service 要建立成 interface, 然後再寫一個 ServiceImpl, 那時資深的工程師告訴我這樣未來拆分微服務時, 比較容易替換 serviceImpl, 用於 restTemplate, gRpc 等實踐.
笑死, 當時根本聽不懂
後來閱讀了 Clean Archticture, DDD 後, 慢慢理解具備 usecase 的設計確實比較容易開發與維護, 同時也容易寫測試, 到最後甚至連 debug 模式都比較少用.
在 Clean Architecture usecase 本質上也是 application-level 的 orchestrator, 用於驅動業務流程, 協調多個 domain service & repository, 甚至是對微服務的交易進行補償.
後來在其他公司工作時, 我曾參與過一個舊的微服務 系統, 但在 api 架構上卻是鏈路式的, 如 order-service, review-service, merchan-service 都對外暴露 api 給前端, 而 api flow 就可能為 frontend -> review -> order or frontend -> merchan -> order 等, 讓微服務之前相互依賴與耦合.
某方面來說也是一種三層架構的慣性思維在微服務情境下自然演化出的產物(是不是很像硬把一個單體服務扯開成微服務?).
鏈路型微服務除了耦合問題之外,在需要跨服務寫入的情境下還會自然演化出分散式交易的問題,而這正是最難處理的部分.
先前在工作以及我自己撰寫 Casha 專案 的時候, 就有使用過 Orchestrated Saga Pattern 來處理分散式交易(有興趣可以參考).
剛好過年期間有空, 就分享一個過去曾看過的反模式, 以及當時我嘗試引入 Backend for Frontedn 作為 orchestrator service 的範例, 當然, 內容都經過簡化與脫敏.
Redis Lock 反模式 -> BFF + Orchestrated Saga Pattern 就用常見的下單 + 扣庫存 兩服務情境為例
業務情境 這次就聚焦兩個微服務之間的分散式交易問題,我刻意簡化為最小可說明的情境.
服務
負責的 DB
職責
order-service
orders 表
管理訂單主資料
inventory-service
inventory 表
管理商品庫存
觸發流程: 前端下單,帶入 productId 與 quantity
order-service 驗證庫存是否充足
order-service 建立訂單記錄
order-service 呼叫 inventory-service 扣減庫存
原始設計 CreateOrderReqDTO
1 2 3 4 5 6 7 8 9 10 11 12 13 @Data public class CreateOrderReqDTO { @NotBlank private String userId; @NotBlank private String productId; @NotNull private Integer quantity; }
OrderService
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 @Service public class OrderService { @Autowired private RedissonClient redissonClient; @Autowired private OrderMapper orderMapper; @Autowired private InventoryFeign inventoryFeign; @Transactional(rollbackFor = Exception.class) public String createOrder (CreateOrderReqDTO req) { String orderNo = IdGenerateUtils.generate(); RLock lock = redissonClient.getLock("order:lock:" + orderNo); try { if (!lock.tryLock(0 , -1 , TimeUnit.SECONDS)) { throw new BizException ("Order is being processed." ); } InventoryDTO inv = inventoryFeign.getInventory(req.getProductId()); if (inv.getAvailableQty() < req.getQuantity()) { throw new BizException ("Insufficient stock." ); } Order order = Order.builder() .orderNo(orderNo) .userId(req.getUserId()) .productId(req.getProductId()) .quantity(req.getQuantity()) .state(OrderState.PENDING) .build(); orderMapper.insert(order); DeductReqDTO deductReq = DeductReqDTO.builder() .orderNo(orderNo) .productId(req.getProductId()) .quantity(req.getQuantity()) .build(); ApiResponse<Void> resp = inventoryFeign.deduct(deductReq); if (!resp.isSuccess()) { throw new BizException ("Deduct inventory failed!" ); } return orderNo; } catch (InterruptedException e) { throw new BizException ("Lock error." ); } finally { if (lock.isHeldByCurrentThread()) lock.unlock(); } } }
問題 乍看之下沒什麼問題, Transactional 內保護本地 order 的寫入, 再仰賴 inventoryFeign 的 ApiResponse 判斷是否要 rollBack.
老實說, 在非極限的場景, 這套程式都是可以正常運作的, 但我們追求的不只是這樣對吧, 同時若這個程式是包含高流量, 金流或 wallet, 是不是就不敢這麼放鬆了.
Q1: @Transactional 假保護 Spring 的 @Transactional 只管理自己服務的 DB connection,對其他獨立服務已 commit 的資料沒有任何影響力.
整個方法結束才 commit 本地 DB,但 inventory-service 在 Step 3 時就已經各自 commit 了。
執行時序:
order-service DB: Start -> INSERT orders(未 commit) …
inventory-service DB: 收到 RPC -> 扣減庫存 -> commit 已完成
order-service DB: … -> commit (若這步失敗,庫存已扣但訂單不存在)
Q2: TTL = -1,鎖永不過期 這個印象很深刻, 當時的同事說是參考某一隻功能複製過來的, 也不想微調.
1 2 lock.tryLock(0 , -1 , TimeUnit.SECONDS)
若 JVM 在執行 RPC 期間 crash, 這把鎖就永遠不會被釋放, 同一筆 orderNo 至此所有請求都拿不到鎖,業務卡死只能靠人工刪除 Redis key。
Q3: 查詢結果作為強一致性依據 Step 1 查詢到庫存充足, 到 Step 3 實際扣減之間存在時間窗口, 這段時間其他請求可能已消耗庫存,查詢結果早已失效,但程式碼卻以此繼續執行。真正的庫存保護應該在扣減時進行。
另外在高併發交易情境, 多數也會靠 redis 預熱資訊並儲存庫存數量, 將步驟 1 搬到 redis 內, 在於步驟 3 DB redis 同步更新庫存, 但非高併發情境下, 上面的做法其實也滿常見的.
Q4: 三大分散式交易失敗情境 正因為是微服務, 我們需要考量到服務之間失敗的情況與最終一致的機制.
統整一下, 情境 A 至少拋出 exception,有 log 可以追查,有機會重試, 情境 C 的 @Transactional rollback 是靜默發生的,API 可能仍回傳成功.
(情境 C 可能是 DB connection 斷了、JVM OOM、網路瞬斷、或者任何導致 commit 失敗的原因)
使用者以為下單成功,庫存已扣,訂單卻不存在, 這類不一致可能數天後在對帳時才發現,且難以自動修復。
改造方案:BFF + Orchestrated Saga 架構說明 1 2 3 4 5 6 7 8 前端 └─ BFF Orchestrator(唯一入口,持有 use case 邏輯,持久化 saga_state) ├─ order-service(只負責 orders 表) │ ├─ createOrder -> Saga Step 1 │ └─ cancelOrder -> Compensating Transaction └─ inventory-service(只負責 inventory 表) ├─ deduct -> Saga Step 2 └─ restore -> Compensating Transaction
兩個下游服務彼此不認識,不互相呼叫,邊界完全乾淨。
DB Schema BFF:saga_state 表
1 2 3 4 5 6 7 8 9 10 11 CREATE TABLE saga_state ( saga_id VARCHAR (64 ) PRIMARY KEY , order_no VARCHAR (64 ) NOT NULL , current_step VARCHAR (32 ) NOT NULL , status VARCHAR (20 ) NOT NULL , payload TEXT NOT NULL , created_at DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP , updated_at DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP );
order-service / inventory-service:idempotency_record 表(各服務獨立持有)
1 2 3 4 CREATE TABLE idempotency_record ( idempotency_key VARCHAR (128 ) PRIMARY KEY , created_at DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP );
設計說明: idempotency_record 同時承擔兩個用途:sagaId:STEP1、sagaId:STEP2);sagaId:STEP2 確認 deduct 是否執行)。
DTO RestoreReqDTO.java
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @Data @Builder public class RestoreReqDTO { private String orderNo; private String productId; private Integer quantity; private String idempotencyKey; private String deductIdempotencyKey; }
其餘 DTO(CreateOrderReqDTO、DeductReqDTO、CancelOrderReqDTO)結構類似,各自攜帶自己的 idempotencyKey。
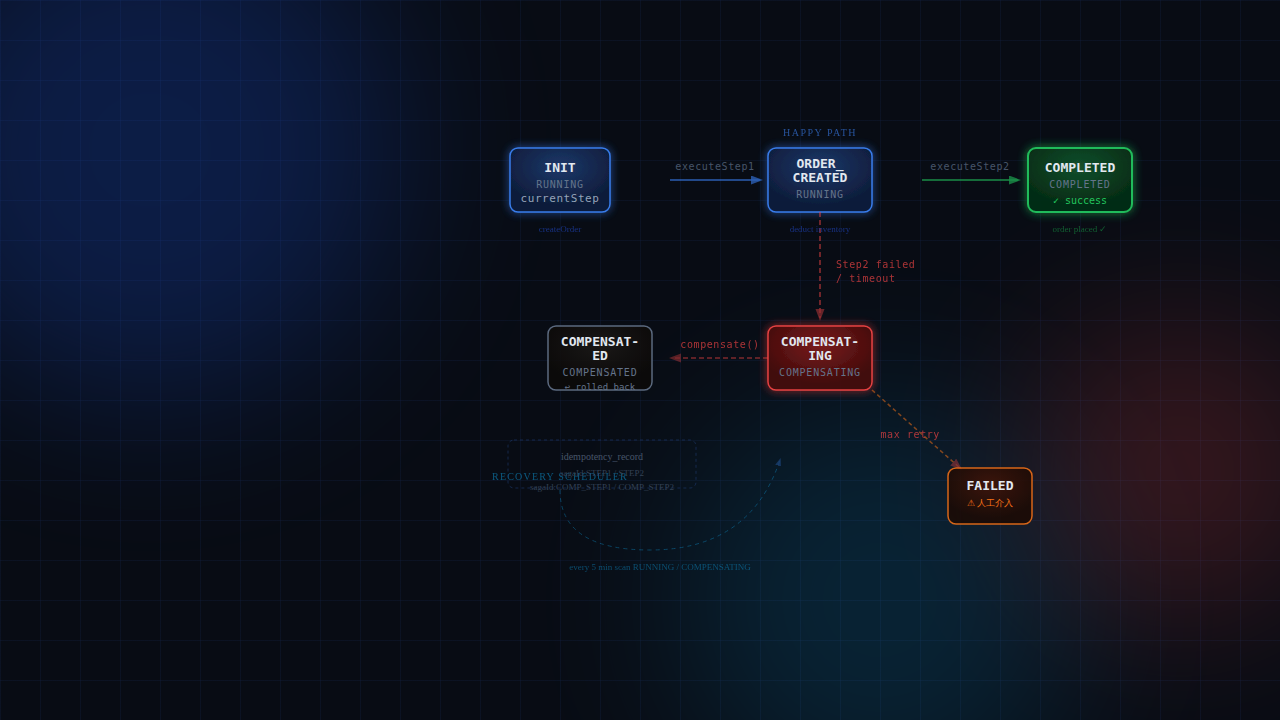
3.4 BFF Orchestrator executeStep1 和 executeStep2 各自封裝 RPC 呼叫與狀態更新,確保無論是正向流程還是 recovery 流程呼叫,currentStep 的維護行為完全一致。
compensate() 只負責執行補償動作,不負責狀態轉換,狀態轉換由呼叫方在呼叫前處理,確保正向流程失敗和 recovery 兩條路徑的狀態管理不衝突。
PlaceOrderOrchestrator.java
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 @Service public class PlaceOrderOrchestrator { @Autowired private SagaStateRepository sagaStateRepo; @Autowired private OrderFeign orderFeign; @Autowired private InventoryFeign inventoryFeign; public String placeOrder (PlaceOrderReqDTO req) { String sagaId = UUID.randomUUID().toString(); String orderNo = IdGenerateUtils.generate(); sagaStateRepo.save(SagaState.builder() .sagaId(sagaId).orderNo(orderNo) .currentStep("INIT" ).status("RUNNING" ) .payload(JSON.toJSONString(req)) .build()); try { executeStep1(sagaId, orderNo, req); executeStep2(sagaId, orderNo, req); return orderNo; } catch (Exception e) { log.error("Saga failed, sagaId={}, start compensating" , sagaId, e); sagaStateRepo.updateStatus(sagaId, "COMPENSATING" , null ); compensate(sagaId, orderNo, req); throw new BizException ("Order failed: " + e.getMessage()); } } void executeStep1 (String sagaId, String orderNo, PlaceOrderReqDTO req) { CreateOrderReqDTO dto = CreateOrderReqDTO.builder() .orderNo(orderNo).userId(req.getUserId()) .productId(req.getProductId()).quantity(req.getQuantity()) .idempotencyKey(sagaId + ":STEP1" ) .build(); call(orderFeign.createOrder(dto), "Step1 createOrder failed" ); sagaStateRepo.updateStep(sagaId, "ORDER_CREATED" ); } void executeStep2 (String sagaId, String orderNo, PlaceOrderReqDTO req) { DeductReqDTO dto = DeductReqDTO.builder() .orderNo(orderNo).productId(req.getProductId()) .quantity(req.getQuantity()) .idempotencyKey(sagaId + ":STEP2" ) .build(); call(inventoryFeign.deduct(dto), "Step2 deductInventory failed" ); sagaStateRepo.updateStatus(sagaId, "COMPLETED" , "COMPLETED" ); } void compensate (String sagaId, String orderNo, PlaceOrderReqDTO req) { SagaState saga = sagaStateRepo.findById(sagaId); if ("ORDER_CREATED" .equals(saga.getCurrentStep())) { compensateRestoreInventory(sagaId, orderNo, req); compensateCancelOrder(sagaId, orderNo); } sagaStateRepo.updateStatus(sagaId, "COMPENSATED" , null ); } private void compensateRestoreInventory (String sagaId, String orderNo, PlaceOrderReqDTO req) { try { RestoreReqDTO dto = RestoreReqDTO.builder() .orderNo(orderNo) .productId(req.getProductId()) .quantity(req.getQuantity()) .idempotencyKey(sagaId + ":COMP_STEP2" ) .deductIdempotencyKey(sagaId + ":STEP2" ) .build(); inventoryFeign.restore(dto); } catch (Exception e) { log.error("Compensate restore failed, sagaId={}" , sagaId, e); } } private void compensateCancelOrder (String sagaId, String orderNo) { try { CancelOrderReqDTO dto = CancelOrderReqDTO.builder() .orderNo(orderNo) .idempotencyKey(sagaId + ":COMP_STEP1" ) .build(); orderFeign.cancelOrder(dto); } catch (Exception e) { log.error("Compensate cancelOrder failed, sagaId={}" , sagaId, e); } } private void call (ApiResponse<Void> resp, String errMsg) { if (!RespCodeEnum.SUCCESS.getCode().equals(resp.getCode())) { throw new BizException (errMsg + ": " + resp.getMessage()); } } }
order-service 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 @Service public class OrderService { @Autowired private OrderMapper orderMapper; @Autowired private IdempotencyRepository idempotencyRepo; @Transactional(rollbackFor = Exception.class) public void createOrder (CreateOrderReqDTO req) { if (idempotencyRepo.exists(req.getIdempotencyKey())){ return ; } orderMapper.insert(Order.builder() .orderNo(req.getOrderNo()).userId(req.getUserId()) .productId(req.getProductId()).quantity(req.getQuantity()) .state(OrderState.PENDING) .build()); idempotencyRepo.save(req.getIdempotencyKey()); } @Transactional(rollbackFor = Exception.class) public void cancelOrder (CancelOrderReqDTO req) { if (idempotencyRepo.exists(req.getIdempotencyKey())) return ; orderMapper.update(null , new UpdateWrapper <Order>() .eq("order_no" , req.getOrderNo()) .set("state" , OrderState.CANCELLED)); idempotencyRepo.save(req.getIdempotencyKey()); } }
inventory-service 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 @Service public class InventoryService { @Autowired private InventoryMapper inventoryMapper; @Autowired private IdempotencyRepository idempotencyRepo; @Transactional(rollbackFor = Exception.class) public void deduct (DeductReqDTO req) { if (idempotencyRepo.exists(req.getIdempotencyKey())) return ; int updated = inventoryMapper.deductWithCheck( req.getProductId(), req.getQuantity()); if (updated == 0 ) { throw new BizException ("Insufficient stock: " + req.getProductId()); } idempotencyRepo.save(req.getIdempotencyKey()); } @Transactional(rollbackFor = Exception.class) public void restore (RestoreReqDTO req) { if (idempotencyRepo.exists(req.getIdempotencyKey())) return ; boolean deducted = idempotencyRepo.exists(req.getDeductIdempotencyKey()); if (deducted) { inventoryMapper.restore(req.getProductId(), req.getQuantity()); } idempotencyRepo.save(req.getIdempotencyKey()); } }
1 2 3 4 5 UPDATE inventorySET available_qty = available_qty - #{quantity}WHERE product_id = #{productId} AND available_qty >= #{quantity}
Strategy + Map 替換 Switch Case 大家莫忘 K 老弟受過的苦難
為什麼要替換 Saga 的 recoverSaga 很容易寫成大型 switch case:
1 2 3 4 5 6 switch (saga.getCurrentStep()) { case "INIT" : case "ORDER_CREATED" : case "COMPENSATING" : }
每新增一個 Saga step,就必須回來修改這個方法, 這是 God Service 的常見前兆——隨著業務增長,這個 switch 會持續膨脹,最終變成一個沒有人敢動的核心方法, 關於 switch case 如何衍生 God Service,以及更系統性的重構思路,可以參考另一篇文章 的討論。
當然可能這個業務若評斷改動不大, 真的去用 switch case 也是可以的, 這裡我們用 Strategy + Map 來解決它。
StepRecoveryHandler interface 1 2 3 public interface StepRecoveryHandler { void recover (SagaState saga, PlaceOrderReqDTO req) ; }
各 Step 的 Handler 實作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 @Component public class InitStepRecoveryHandler implements StepRecoveryHandler { @Autowired private PlaceOrderOrchestrator orchestrator; @Override public void recover (SagaState saga, PlaceOrderReqDTO req) { log.info("Recovery from INIT, sagaId={}" , saga.getSagaId()); orchestrator.executeStep1(saga.getSagaId(), saga.getOrderNo(), req); orchestrator.executeStep2(saga.getSagaId(), saga.getOrderNo(), req); } } @Component public class OrderCreatedStepRecoveryHandler implements StepRecoveryHandler { @Autowired private PlaceOrderOrchestrator orchestrator; @Autowired private SagaStateRepository sagaStateRepo; @Override public void recover (SagaState saga, PlaceOrderReqDTO req) { log.info("Recovery from ORDER_CREATED, sagaId={}" , saga.getSagaId()); try { orchestrator.executeStep2(saga.getSagaId(), saga.getOrderNo(), req); } catch (Exception e) { log.warn("Step2 retry failed, start compensating, sagaId={}" , saga.getSagaId()); sagaStateRepo.updateStatus(saga.getSagaId(), "COMPENSATING" , null ); orchestrator.compensate(saga.getSagaId(), saga.getOrderNo(), req); } } } @Component public class CompensatingStepRecoveryHandler implements StepRecoveryHandler { @Autowired private PlaceOrderOrchestrator orchestrator; @Override public void recover (SagaState saga, PlaceOrderReqDTO req) { log.info("Recovery from COMPENSATING, sagaId={}" , saga.getSagaId()); orchestrator.compensate(saga.getSagaId(), saga.getOrderNo(), req); } }
SagaRecoveryService:查表取代 switch 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 @Service public class SagaRecoveryService { @Autowired private SagaStateRepository sagaStateRepo; @Autowired private Map<String, StepRecoveryHandler> recoveryHandlers; private static final Map<String, String> STEP_HANDLER_MAP = Map.of( "INIT" , "initStepRecoveryHandler" , "ORDER_CREATED" , "orderCreatedStepRecoveryHandler" , "COMPENSATING" , "compensatingStepRecoveryHandler" ); public void recoverSaga (SagaState saga, PlaceOrderReqDTO req) { String handlerName = STEP_HANDLER_MAP.get(saga.getCurrentStep()); if (handlerName == null ) { log.error("No recovery handler for step={}, sagaId={}" , saga.getCurrentStep(), saga.getSagaId()); sagaStateRepo.markFailed(saga.getSagaId()); return ; } StepRecoveryHandler handler = recoveryHandlers.get(handlerName); handler.recover(saga, req); } }
Orchestrator Crash 防護:恢復排程 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 @Component public class SagaRecoveryScheduler { @Autowired private SagaStateRepository sagaStateRepo; @Autowired private SagaRecoveryService sagaRecoveryService; @Scheduled(fixedDelay = 300_000) public void recover () { List<SagaState> stuck = sagaStateRepo.findStuck( List.of("RUNNING" , "COMPENSATING" ), LocalDateTime.now().minusMinutes(10 )); for (SagaState saga : stuck) { log.warn("Recovering saga={}, step={}, status={}" , saga.getSagaId(), saga.getCurrentStep(), saga.getStatus()); try { PlaceOrderReqDTO req = JSON.parseObject( saga.getPayload(), PlaceOrderReqDTO.class); sagaRecoveryService.recoverSaga(saga, req); } catch (Exception e) { log.error("Recovery failed, saga={}" , saga.getSagaId(), e); sagaStateRepo.markFailed(saga.getSagaId()); } } } }
狀態轉換總覽 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 正向流程成功: RUNNING(INIT) -> RUNNING(ORDER_CREATED) -> COMPLETED(COMPLETED) 正向流程失敗(Step 2 失敗或 timeout): RUNNING(ORDER_CREATED) -> [呼叫方] COMPENSATING(ORDER_CREATED) -> [compensate()] COMPENSATED(ORDER_CREATED) Recovery - INIT: RUNNING(INIT) -> [executeStep1] RUNNING(ORDER_CREATED) -> [executeStep2] COMPLETED(COMPLETED) Recovery - ORDER_CREATED(Step 2 重試成功): RUNNING(ORDER_CREATED) -> [executeStep2] COMPLETED(COMPLETED) Recovery - ORDER_CREATED(Step 2 重試失敗): RUNNING(ORDER_CREATED) -> [handler] COMPENSATING(ORDER_CREATED) -> [compensate()] COMPENSATED(ORDER_CREATED) Recovery - COMPENSATING: COMPENSATING(ORDER_CREATED) -> [compensate()] COMPENSATED(ORDER_CREATED)
改造前後對比
改造前(Redis Lock + RPC)
改造後(BFF + Orchestrated Saga)
交易保護
@Transactional 包住跨服務 RPC,假保護
每步操作是獨立的 local transaction
鎖持有時間
所有 RPC 時間加總
每個服務只持有自己 local tx 的時間
Crash 處理
TTL = -1,鎖永久不釋放
saga_state 持久化,crash 後自動恢復
失敗處理
情境 C 靜默不一致,無告警
所有失敗可觀測,有明確補償路徑
庫存一致性
查詢結果作為強一致性依據
扣減時用樂觀鎖真正保證
服務職責
order-service 兼領域邏輯與流程協調
BFF 持有流程,下游服務只負責自己領域
服務依賴
兩服務直接互相依賴
兩服務彼此不認識,邊界完全乾淨
BFF 作為 Orchestration Layer 其實在實際工作中提案 BFF + Orchestrated Saga 時還是遭遇一些質疑,使我對這個架構選擇有更深入的思考。
效能多一層會不會變差? 不過這個質疑的前提是原本的設計效能就是好的 ,但事實並非如此。
鏈路式 API(原本)vs BFF(改造後)的 thread 佔用
1 2 3 4 5 6 7 鏈路式(order-service 直接呼叫 inventory-service): Thread 佔用時間 = 本地處理 + RPC 時間 + 鎖持有時間(橫跨整條鏈路) 高並發下:鎖競爭 + 長時間持鎖 = 嚴重瓶頸 BFF 同步阻塞: Thread 佔用時間 = Step1 RPC + Step2 RPC(串行 Saga steps) 無跨服務鎖,每步完成即釋放,不存在鏈路式的鎖競爭問題
多一個服務的內部網路延遲通常在 1ms 以內,相對於業務邏輯和 DB 操作幾乎可以忽略。真正的效能差異來自鎖的消除,而不是多一層 api 的時間。
同步阻塞在高並發下的 thread pool 壓力:
BFF 同步等待兩個 RPC 回來,確實意味著每個請求都會佔用一條 thread 直到流程結束, 這是真實存在的代價, 特別是當業務未來大到有多個 RPC.
常見的解法是靠水平擴展去對沖, 由於 BFF 本身是無狀態的(所有狀態都在 saga_state DB),任意副本可以處理任意請求,可以根據負載動態增加副本數, 但前提是 saga_state DB 本身不能成為新的瓶頸,需要有對應的連線池和讀寫分離設計。
至於改用 WebFlux 非同步非阻塞,理論上可以大幅提升吞吐量,但 Saga 的錯誤處理和補償邏輯在 reactive 模式下複雜度會大幅上升,對大多數團隊來說維護成本超過吞吐量的收益。這是工程上的 trade-off,不是技術能力問題。
BFF 變成大型 Usecase 算不算耦合? 其實這也是我最擔心的一點, 最初 BFF 的設計其實是一個 aggregation layer, 用於聚合資料, 避免前端直接耦合微服務, 但也因爲 BFF 是 Application Layer 的最外層, 使他自然演化成 orchestration Layer, 詳細的 BFF 概念可以參考 BFF 之父 Sam Newman (他也是 Building Microservices 的作者).
到後期 BFF 可能會變一個巨大的 usecase, 而我想關鍵區別在於依賴的方向:
1 2 3 4 原本:order-service <---> inventory-service(雙向,互相知道對方) 改造後: BFF -> order-service BFF -> inventory-service(單向)
order-service 和 inventory-service 之間的邊界是真正乾淨的。BFF 確實耦合了下游,但這個協調的複雜度本來就存在,只是從散落在各服務之間,集中到一個有明確職責的地方。集中管理比分散耦合更容易維護、測試和監控。
BFF 肥大的風險與邊界 綜上所述, 我認為 BFF 兼任 Orchestration Layer 是合理的定位,但需要守住一些邊界,否則 BFF 會從協調者退化成一顆單體服務, 後面的 Biz-Service 都變成 respository.
BFF 開始失控的信號基本上有:
BFF 直接操作業務 DB : 代表它不再只是協調者,相關邏輯應拆到對應服務, 因此過往在設計銀行架構的時候, 會把它安置於 tier 1 ~ tier 2 防火前之間, 只能連線 SagaState DB.BFF 內出現大量業務規則判斷 : 例如說 VIP 用戶走 A 流程,一般用戶走 B 流程,領域規則應下推到對應服務,BFF 只負責呼叫哪個流程,不負責規則本身。BFF 內的 use case 之間互相依賴 : 每個 use case 應該是獨立可測試的單元。
BFF 通常是肥在:
流程協調邏輯:決定呼叫哪些服務、以什麼順序、在什麼條件下補償
查詢聚合邏輯:並行呼叫多個服務,組合結果回傳給前端
Saga 狀態管理:持久化每一步的執行狀態,驅動恢復排程
跨服務的 use case 入口:每個業務操作都有一個明確的 Orchestrator 方法對應
BFF 成為新單點的問題 當 BFF 作為聚合服務後, 所有的請求都會經過他才往後送, 確實可能成為效能瓶頸.
對沖方法是用 BFF 無狀態多副本部署,狀態全部持久化在 saga_state DB。任一副本 crash 不影響其他副本繼續服務,恢復排程在任意存活副本上運行,可以繼續處理未完成的 Saga。補償失敗需要告警機制,超過重試次數應標記 FAILED 並通知人工介入。
結語 有可能是我最早接觸的微服務就是走 BFF Pattern, 每當看到由前端直接打往各項服務時我都會充滿疑惑, 我想引入 BFF + Orchestrated Saga 解決的不是效能問題,也不是一般意義上的解耦, 而是解決失敗語義的問題 :
把靜默、不可修復的不一致變成可觀測、有明確補償路徑的失敗
在對資料一致性要求高的場景,這個改變的價值遠超過它帶來的開發複雜度。
至於 BFF 肥大我覺得本身不是問題,肥在錯誤的東西上才是問題 。流程協調和 use case 組合放在 BFF 是對的,領域規則和 DB 操作不應該在 BFF,這條線守住,BFF 就不會失控。
而且當 BFF 真的大到有過多邏輯時, 我們甚至可以在 BFF 和 Biz 之間設計獨立的 Orchestrator-Service 來解耦, 不過那應該也是 FAANG 的程度了吧~
學習重點 最後讓 AI 幫我劃重點, 謝謝你閱讀到最後:
Redis Lock 只能解決並發衝突 ,無法處理部分失敗的補償,這是兩個完全不同的問題。@Transactional 只管理自己服務的 DB connection ,對其他服務已 commit 的資料沒有任何影響力。情境 C(A commit 失敗)是最危險的反模式 ,因為它是靜默發生的,系統沒有任何告警信號。補償的原則是保守執行 :timeout 時無法得知對方是否成功,必須嘗試補償,讓冪等設計吸收重複呼叫。idempotency_record 一張表解決兩個問題 :防止正向操作重複執行,以及供補償操作確認正向操作是否曾執行過,key 格式的設計是關鍵。方法的職責邊界必須清楚 :compensate() 只執行補償動作,狀態轉換由呼叫方負責,確保多個呼叫路徑行為一致。Saga 的核心價值 :承認跨服務不可能有 ACID,改用可觀測的失敗加上補償,取代靜默的不一致。Idempotency Key 必須與業務資料在同一個 local transaction commit ,才能真正保證冪等性。Strategy + Map 取代大型 switch case :每個 step 的處理邏輯封裝在獨立的 Handler,新增 step 不需要修改現有程式碼,避免 God Service 的形成。BFF 的單向依賴 比原本服務之間的雙向耦合更清晰、更容易維護;它的效能代價(同步阻塞)靠無狀態水平擴展對沖。