今天來記錄一下在過去工作之中曾看過的 api retry 作法, 以及後續的更新與優化。
前言
之前在工作中曾經有更新過一個需求, 流程上是當用戶在系統內提交訂單後, 會建立 Task 任務到 DB 內, 再由排程系統定時執行任務, 把資料送往第三方檢驗。
當時的更新只是將 response 內增加的參數儲存到 DB 內, 但卻讓我看到了一段 Legacy Code, 秉持著工程師的優良傳統, 能動且 QA 測過 ok 就不要給我動他, 我把參數補進 DB 並提交 PR 後, 這件事就一直被我埋藏在心裡, 偶而無聊時還會翻出來想一想, 跟前女友一樣, 想著今天 2026 第一天該給他一個了結了, 便重新寫出來並優化看看。
核心邏輯
直接看程式, 當 job 被觸發時, 到 DB 內撈取狀態為 Pending 的 Tasks, 逐一將內部資料發送給 third party api, 成功後更新狀態, 若發送失敗, 則等待 5 秒後重試, 直到重試滿三次後, 更新該任務為 retry 失敗到 DB 內。
補充一下該任務是固定在半夜執行, 並只有單一節點, 無併發 (SI 公司的傑作)
程式是依照我的回憶, 因為只要討論 job & retry 機制, 故有少一些錯誤處理的機制
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| public void executeTasks() {
List<Task> taskList = taskRepository.findPendingTasks();
int maxRetry = 3;
for (Task task : taskList) {
boolean success = false;
while (task.getRetryCount() <= maxRetry && !success) {
try {
task.increaseRetryCount();
ThirdPartyRs response = thirdPartyClient.sendTaskData(task);
success = true;
task.markSuccess(response);
} catch (Exception e) {
log.warn("Task failed, TaskId: {}, retryCount={}", task.getId, task.getRetryCount());
try {
Thread.sleep(5000);
} catch (InterruptedException ie) {
Thread.currentThread().interrupt();
break;
}
}
}
if (!success && task.getRetryCount() >= maxRetry) {
task.markRetryFailed();
}
taskRepository.save(task);
}
}
|
問題所在
嗯…, 乍看之下都說得通, 但就覺得哪裡怪怪的。
1. 用同步流程處理時間型問題
這段 code 本質上是用 CPU thread 當計時器, 乍看之下,每一個 Task 可能就花個幾秒的時間, 但問題在於這個時間是會被累加的。
最常見的是第三方系統整體異常, 此時所有 Task 的請求都會失敗, 此時整個 Job 的執行時間會變成:
總時間 ≈ Task 數量 × 每個 Task 的 retry 等待時間
假設我有 500 筆 Task, 每個 Task sleep 15 秒, 500 × 10 秒 = 5000 秒 ≈ 2 小時, 多可怕的數字。
這時就找到問題癥結點了, 這段程式隱含了一個假設:
第三方系統偶爾失敗,而且會很快恢復 (你信嗎?)
其實我覺得這種情況下的 retry 已經沒有任何意義.
這也是同步 retry 最大的盲點, 它無法感知整體失敗狀態, 即使每一行程式碼都正確,同步 retry 仍然可能因為失敗的數量而拖垮整個 Job, 更糟的是,如果排程系統本身有 timeout 或 watchdog, 這個 Job 很可能在尚未處理完所有 Task 時被強制中斷, 讓系統狀態變得難以判讀。
故此時使用非同步 retry 或 Delay Queue 並搭配狀態驅動設計會是更佳的作法, 也是我們待會會提及的優化方法。
2. 依賴過多假設
當前的設計依賴了很多的定義, 如:
- Job 只跑一次, 重跑機制在其他地方處理
- 不會改成兩個節點
- 不會改成白天跑
- 預設第三方系統失敗後很快會恢復
同時也會發現, 這個設計有很多不細緻的地方(當然也因為是我回憶的關係, 會少一些內容), 拿出來和各位年薪 200w + 的紳士們可以討論一個下午。
但我們是否有想過, 為什麼當時工程師會寫住這樣的程式呢?
是不是一問 PM 三不知, 沒有第三方的 api 狀態文件, 隕石開發上午給需求下午要測試, 工程師待遇不好(雖然我劃掉但是這個機率還是很高的) ?
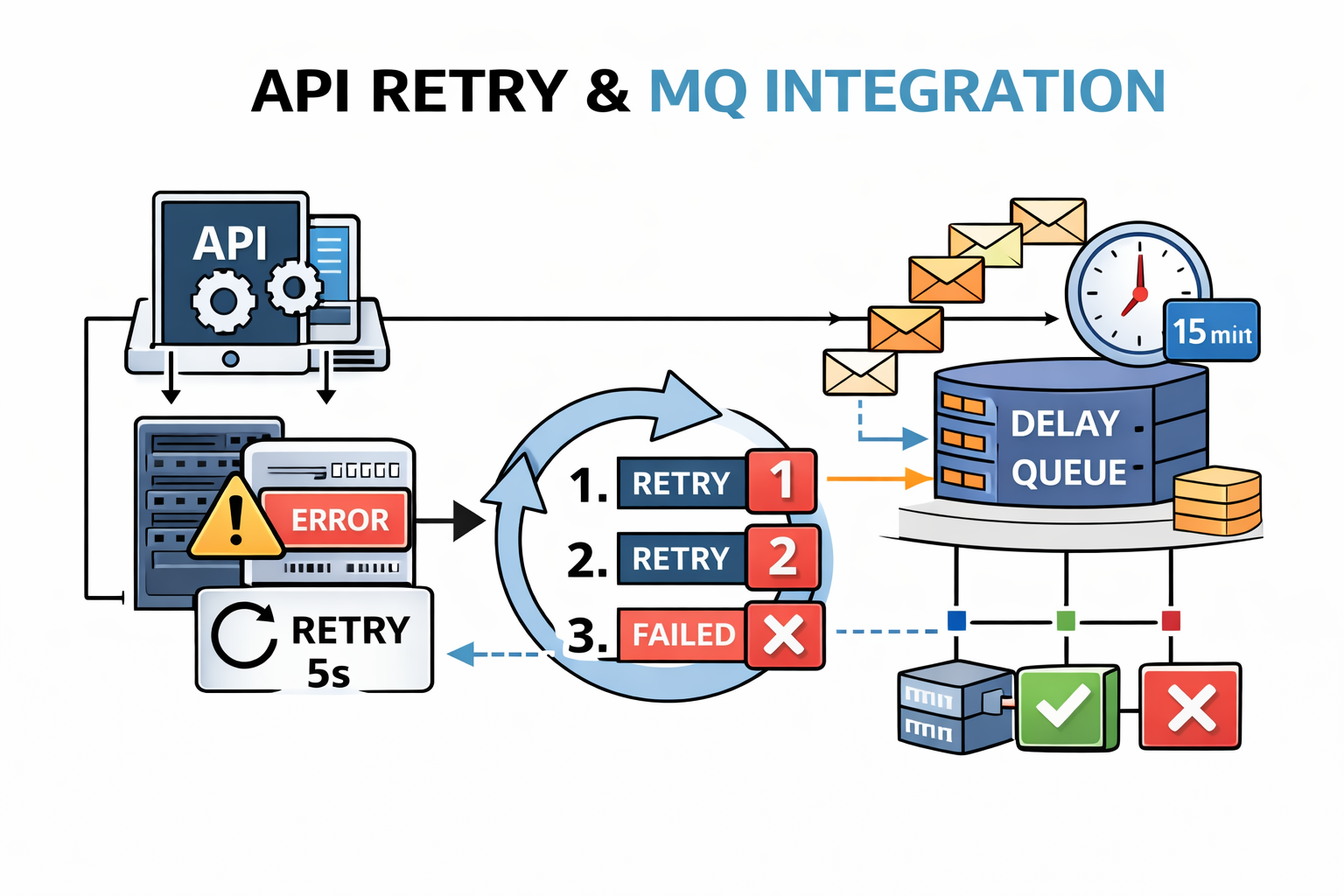
Delay Queue 解耦與優化
那倘若現在有一個機會能優化呢?
回到一開始的問題, 對於這種第三方系統的 retry,實際上不用立刻再試一次, retry 成不成功,往往取決於什麼時候再試。
Redesign with MQ
開始前我們先考量到, 因為第三方系統的失敗,很少是瞬間恢復的, 故會採用階梯狀 retry, 同時靠 MQ 不會讓 Job 執行時間線性膨脹, retry 行為自然被攤平在時間軸上.
我們把流程加入 Delay Message, 更新為:
首次發送
- 由 Job 觸發
- 嘗試將資料送往第三方系統
- 若成功,更新 Task 狀態為 SUCCESS
首次失敗
- 不立刻 retry
- 將 Task 狀態更新為 RETRY_WAITING
- 發送一筆 Delay Message 到 MQ(設定時間為 15 分鐘後)
Delay 到期
- MQ consumer 被觸發
- 重新從 DB 讀取 Task 狀態與 retry 次數
- 若仍可 retry,進行下一次嘗試
- 若失敗,更新 retry 次數,並再次送出 Delay Message
重複上述流程
- 每次 retry 間隔逐步拉長
- 直到成功,或 retry 次數達上限
retry 用盡
- 明確標記 Task 為 RETRY_FAILED
- 結束流程,等待人工處理或後續補償機制
Job
來看程式, 首先是 Job 只負責第一次 api 發送:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| public class TaskJob {
private static final int MAX_RETRY = 3;
private final TaskRepository taskRepository;
private final ThirdPartyClient thirdPartyClient;
private final RetryMessageProducer retryProducer;
public void execute() {
List<Task> tasks = taskRepository.findByStatus(TaskStatus.PENDING);
for (Task task : tasks) {
tryFirstAttempt(task);
}
}
private void tryFirstAttempt(Task task) {
try {
task.increaseRetry();
ThirdPartyRs response = thirdPartyClient.sendTaskData(task);
task.markSuccess(response);
taskRepository.save(task);
} catch (Exception e) {
log.warn("Task failed, TaskId: {}", task.getId);
if (task.canRetry(MAX_RETRY)) {
task.markRetryWaiting();
taskRepository.save(task);
retryProducer.sendDelay(task.getId(), task.getRetryCount());
} else {
task.markRetryFailed(e);
taskRepository.save(task);
}
}
}
}
|
Delay Producer
做階梯式延遲。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| public class RetryMessageProducer {
private final MessageQueueClient mqClient;
public RetryMessageProducer(MessageQueueClient mqClient) {
this.mqClient = mqClient;
}
public void sendDelay(Long taskId, int retryCount) {
long delayMillis = calculateDelay(retryCount);
RetryMessage message = new RetryMessage(taskId, retryCount);
mqClient.sendDelayed(
"task-retry-topic",
message,
delayMillis
);
}
private long calculateDelay(int retryCount) {
switch (retryCount) {
case 1:
return TimeUnit.MINUTES.toMillis(15);
case 2:
return TimeUnit.MINUTES.toMillis(30);
case 3:
return TimeUnit.MINUTES.toMillis(45);
default:
return 0;
}
}
}
|
MQ Consumer
每次 retry 都重新讀 DB, 以 Status 為判斷核心.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| public class RetryConsumer {
private static final int MAX_RETRY = 3;
private final TaskRepository taskRepository;
private final ThirdPartyClient thirdPartyClient;
private final RetryMessageProducer retryProducer;
public void onMessage(RetryMessage message) {
Task task = taskRepository.findById(message.getTaskId());
if (task.getStatus() != TaskStatus.RETRY_WAITING) {
return;
}
if (task.getRetryCount() != message.getRetryCount()) {
return;
}
try {
task.increaseRetry();
thirdPartyClient.send(task);
task.markSuccess();
taskRepository.save(task);
} catch (Exception e) {
if (task.canRetry(MAX_RETRY)) {
task.markRetryWaiting();
taskRepository.save(task);
retryProducer.sendDelay(task.getId(), task.getRetryCount());
} else {
task.markRetryFailed();
taskRepository.save(task);
}
}
}
}
|
結語
在這個設計中,retry 不再是一段程式碼,而是一段被攤平在時間軸上的行為, 透過 MQ,我們把 retry 從同步流程中拆出來, Job 只負責第一次嘗試, retry 被攤平在時間軸上, 每一次 retry 都重新以 DB 狀態作為判斷依據。
但寫到這裡,其實也很難不回頭問一個問題:
到底這個程式是如何誕生的?
多半不是因為能力不足,而是因為現實條件往往讓人感到沮喪:
- 需求與規格文件模糊,第三方行為全靠通靈
- PM 對各種情境描述模糊(你家是測案包含在規格內的嗎? 還是你測完 QA 做一樣的事情?)
- 開發時間被壓縮到先能動再說
- 系統上線的優先順序,永遠高於設計完整性
而且寫成 Mq, 也仰賴開發環境與 test 環境的 middleware 支持, 需要撰寫的程式也變多, 測試的維度也增加。
在這樣的背景下,能動就好反而成為一種最理性的選擇, 又或是在他的時空背景下, 這樣的設計反而是最佳的選擇, 只是隨著時間推移,這些選擇會慢慢堆疊,最後變成前人不想碰, 後人不敢改, 系統靠補丁活著.
於是我們開始稱它為 Legacy Code.
其實我寫這篇文章並不是要否定過去的實作,而是想記錄一個過程, 如果我是一個很有經驗的工程師, 在開發時是否就能靠對系統與 api 的經驗去避免上述問題?